Recentemente, fui ver que filmes é que a Netflix me recomendava, tendo em conta as minhas preferências, e deparei-me com filmes sobre alpinismo, guerra, aviões, mergulho no gelo, surf e jogos de apostas. Quer dizer, a Netflix deve achar que eu tenho pelos no peito e vou à caça aos domingos de manhã.
Atualmente, qualquer plataforma online pretende captar a atenção dos utilizadores o máximo de tempo possível.
Quanto mais tempo alguém passar a ver vídeos, mais dinheiro é gerado através de publicidade. Quanto melhores forem as sugestões de produtos de uma loja online, maior será o número de vendas e por aí fora.
Por isso, é importante criar sistemas e algoritmos de recomendação que sugiram aos clientes produtos nos quais eles provavelmente irão estar interessados.
Vamos começar por analisar uma abordagem simples a este problema. No contexto de uma plataforma de streaming, podemos tentar classificar os filmes de acordo com alguns atributos. E podemos quantificar estes atributos numa escala de 0 a 5.
Por exemplo, o filme da Barbie tem muito pouca ação, não é uma biografia, é um filme de comédia, tem pouco mas algum drama e não é um filme erótico. Acho eu.

Ora, nos primórdios da Netflix, era pedido a cada utilizador para preencher um longo questionário com as suas preferências.
O Sr. Casimiro, por exemplo, gosta muito de filmes biográficos e com ação. Não gosta muito de comédias, gosta mais ou menos de dramas e detesta filmes eróticos. Será que o filme da Barbie deve ser sugerido ao Sr. Casimiro?
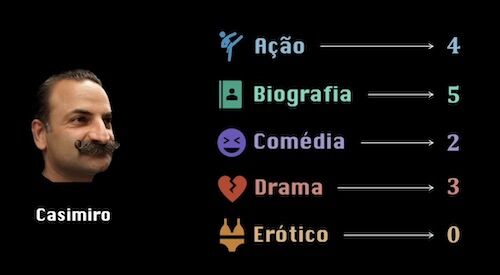
De certa forma, nós podemos quantificar o grau de afinidade entre um filme e uma pessoa. Para tal, podemos representar os atributos de um filme numa matriz linha e as preferências de um utilizador numa matriz coluna.
O grau de correspondência entre um filme e uma pessoa é então obtido multiplicando estas duas matrizes, da forma que se mostra aqui. Neste caso, o grau de correspondência entre o filme da Barbie e o Sr. Casimiro é igual a 18.
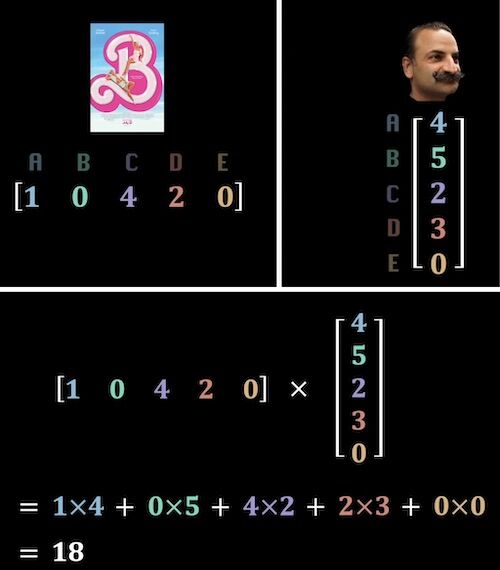
Consideremos agora um outro filme, o Sniper Americano. Trata-se de uma biografia com muita ação e bastante drama.
Se multiplicarmos a matriz dos atributos deste filme pela matriz das preferências do Sr. Casimiro, desta vez obtemos o valor 51, que é superior ao valor 18 que tínhamos obtido anteriormente.
Assim, é mais pertinente recomendar o filme Sniper Americano ao Sr. Casimiro do que o filme da Barbie.

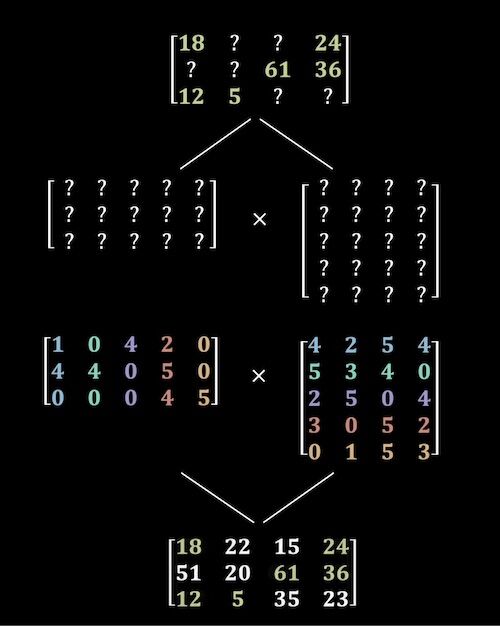
Se considerarmos uma matriz com os atributos dos vários filmes disponíveis e uma matriz com as preferências dos vários utilizadores, a matriz produto indicar-nos-á o grau de correspondência entre um determinado filme e um determinado utilizador.
Por exemplo, o valor que se encontra na segunda linha e na terceira coluna desta matriz indica-nos o grau de correspondência entre o segundo filme e o terceiro utilizador.

Olhem que esta avozinha chinesa engana bem!
No entanto, embora esta abordagem seja fácil de entender, não é muito prática, porque requer que os utilizadores tenham de dizer explicitamente quais são as suas preferências e além de isso dar um trabalho do caraças, às vezes uma pessoa nem sequer sabe bem do que é que gosta.
Por isso, são mais frequentes sistemas de recomendação que têm uma abordagem colaborativa.
A ideia por trás destes algoritmos é que provavelmente eu vou gostar de um filme de que uma pessoa que tem interesses semelhantes aos meus gostou.
Ora, nesta abordagem, em vez de pedirmos os utilizadores para declararem extensivamente quais são as suas preferências, nós pedimos-lhes apenas para atribuírem uma pontuação a filmes que eles já viram.
Por exemplo, o Sr. Casimiro já viu os filmes da Barbie e 50 Sombras de Grey, tendo-lhes atribuído uma pontuação de 18 e 12, respetivamente.Mas ele ainda não viu o Sniper Americano, portanto essa entrada da matriz está por preencher: nós ainda não sabemos se ele vai gostar desse filme.

O objetivo é então tentar adivinhar os valores que vão surgir nas entradas da matriz que ainda estão por preencher.
Para tal, são utilizados métodos de machine learning cujo objetivo é encontrar duas matrizes que, ao serem multiplicadas, dão origem a uma matriz cujas entradas batem certo com aquelas que já haviam sido preenchidas.
Além disso, a matriz irá ser completada, isto é, acaba por ser feita uma previsão dos valores que deverão surgir nas entradas da matriz que até então eram desconhecidas.
Nós vamos desta forma obter estimativas para o grau de satisfação entre um utilizador e um filme que o utilizador ainda não viu. Se o valor previsto for elevado, é uma boa ideia recomendar esse filme a esse utilizador. Obviamente isto é uma abordagem muito simplificada, mas a ideia está lá.
Uma coisa fascinante neste sistema é que os atributos dos filmes não estão fixados à partida — eles emergem dos padrões nos dados.
A moral da história é que estamos todos a ser manipulados por algoritmos e a inteligência artificial irá transformar-nos em criaturas amorfas e acéfalas que deitam leite antes dos cereais.
Nah, estou a brincar.
Bem, eu vou mas é ver filmes sobre os caças da 2ª Guerra Mundial ou lá o que é que a Netflix me anda a recomendar… e até ao próximo artigo.
[w] Instagram | YouTube
[e] [email protected]
- No Vaticano há 2,3 Papas por km². As estatísticas enganam - 10 Maio, 2025
- Como corrigir erros (com um truque matemático) - 20 Março, 2025
- Por que razão escolhemos sempre a fila mais lenta? - 4 Janeiro, 2025











Obrigado Inês por mais uma lufada de informação com boa disposição!